Chapter 1
Data Science and Computing
Introduction
Data are descriptions of the world around us, collected through observation and stored on computers. Computers enable us to infer properties of the world from these descriptions. Data science is the discipline of drawing conclusions from data using computation. There are four core aspects of effective data analysis: visualization, inference, prediction, and modeling. This text develops a consistent approach to all four, introducing statistical ideas and fundamental ideas in computer science concurrently. We focus on a minimal set of core techniques, but demonstrate that they apply to a vast range of real-world applications. A foundation in data science requires not only understanding statistical and computational techniques, but also recognizing how they apply to real scenarios.
For whatever aspect of the world we wish to study---whether it's the Earth's weather, the world's markets, political polls, or the human mind---data we collect typically offer an incomplete description of the subject at hand. The central challenge of data science is to make reliable conclusions using this partial information.
In this endeavor, we will combine two essential tools: computation and randomization. For example, we may want to understand climate change trends using temperature observations. Computers will allow us to use all available information to draw conclusions. Rather than focusing only on the average temperature of a region, we will consider the whole range of temperatures together to construct a more nuanced analysis. Randomness will allow us to consider the many different ways in which incomplete information might be completed. Rather than assuming that temperatures vary in a particular way, we will learn to use randomness as a way to imagine many possible scenarios that are all consistent with the data we observe.
Applying this approach requires learning to program a computer, and so this text interleaves a complete introduction to programming that assumes no prior knowledge. Readers with programming experience will find that we cover several topics in computation that do not appear in a typical introductory computer science curriculum. Data science also requires careful reasoning about quantities, but this text does not assume any background in mathematics or statistics beyond basic algebra. You will find very few equations in this text. Instead, techniques are described to readers in the same language in which they are described to the computers that execute them---a programming language.
Computational Tools
This text uses the Python 3 programming language, along with a standard set of numerical and data visualization tools that are used widely in commercial applications, scientific experiments, and open-source projects. Python has recruited enthusiasts from many professions that use data to draw conclusions. By learning the Python language, you will join a million-person-strong community of software developers and data scientists.
Getting Started. The easiest and recommended way to start writing programs in Python is to log into the companion site for this text, program.dsten.org. If you are enrolled in a course offering that uses this text, you should have full access to the programming environment hosted on that site. The first time you log in, you will find a brief tutorial describing how to proceed.
You are not at all restricted to using this web-based programming environment. A Python program can be executed by any computer, regardless of its manufacturer or operating system, provided that support for the language is installed. If you wish to install the version of Python and its accompanying libraries that will match this text, we recommend the Anaconda distribution that packages together the Python 3 language interpreter, IPython libraries, and the Jupyter notebook environment.
This text includes a complete introduction to all of these computational tools. You will learn to write programs, generate images from data, and work with real-world data sets that are published online.
Statistical Techniques
The discipline of statistics has long addressed the same fundamental challenge as data science: how to draw conclusions about the world using incomplete information. One of the most important contributions of statistics is a consistent and precise vocabulary for describing the relationship between observations and conclusions. This text continues in the same tradition, focusing on a set of core inferential problems from statistics: testing hypotheses, estimating confidence, and predicting unknown quantities.
Data science extends the field of statistics by taking full advantage of computing, data visualization, and access to information. The combination of fast computers and the Internet gives anyone the ability to access and analyze vast datasets: millions of news articles, full encyclopedias, databases for any domain, and massive repositories of music, photos, and video.
Applications to real data sets motivate the statistical techniques that we describe throughout the text. Real data often do not follow regular patterns or match standard equations. The interesting variation in real data can be lost by focusing too much attention on simplistic summaries such as average values. Computers enable a family of methods based on resampling that apply to a wide range of different inference problems, take into account all available information, and require few assumptions or conditions. Although these techniques have often been reserved for graduate courses in statistics, their flexibility and simplicity are a natural fit for data science applications.
Why Data Science?
Most important decisions are made with only partial information and uncertain outcomes. However, the degree of uncertainty for many decisions can be reduced sharply by public access to large data sets and the computational tools required to analyze them effectively. Data-driven decision making has already transformed a tremendous breadth of industries, including finance, advertising, manufacturing, and real estate. At the same time, a wide range of academic disciplines are evolving rapidly to incorporate large-scale data analysis into their theory and practice.
Studying data science enables individuals to bring these techniques to bear on their work, their scientific endeavors, and their personal decisions. Critical thinking has long been a hallmark of a rigorous education, but critiques are often most effective when supported by data. A critical analysis of any aspect of the world, may it be business or social science, involves inductive reasoning --- conclusions can rarely been proven outright, only supported by the available evidence. Data science provides the means to make precise, reliable, and quantitative arguments about any set of observations. With unprecedented access to information and computing, critical thinking about any aspect of the world that can be measured would be incomplete without the inferential techniques that are core to data science.
The world has too many unanswered questions and difficult challenges to leave this critical reasoning to only a few specialists. However, all educated adults can build the capacity to reason about data. The tools, techniques, and data sets are all readily available; this text aims to make them accessible to everyone.
Example: Plotting the Classics
In this example, we will explore statistics for two classic novels: The Adventures of Huckleberry Finn by Mark Twain, and Little Women by Louisa May Alcott. The text of any book can be read by a computer at great speed. Books published before 1923 are currently in the public domain, meaning that everyone has the right to copy or use the text in any way. Project Gutenberg is a website that publishes public domain books online. Using Python, we can load the text of these books directly from the web.
The features of Python used in this example will be explained in detail later in the course. This example is meant to illustrate some of the broad themes of this text. Don't worry if the details of the program don't yet make sense. Instead, focus on interpreting the images generated below. The "Expressions" section later in this chapter will describe most of the features of the Python programming language used below.
First, we read the text of both books into lists of chapters, called huck_finn_chapters and little_women_chapters. In Python, a name cannot contain any spaces, and so we will of often use an underscore _ to stand in for a space. The = in the lines below give a name on the left to the result of some computation described on the right. A uniform resource locator or URL is an address on the Internet for some content; in this case, the text of a book.
# Read two books, fast!
huck_finn_url = 'http://www.gutenberg.org/cache/epub/76/pg76.txt'
huck_finn_text = read_url(huck_finn_url)
huck_finn_chapters = huck_finn_text.split('CHAPTER ')[44:]
little_women_url = 'http://www.gutenberg.org/cache/epub/514/pg514.txt'
little_women_text = read_url(little_women_url)
little_women_chapters = little_women_text.split('CHAPTER ')[1:]
While a computer cannot understand the text of a book, we can still use it to provide us with some insight into the structure of the text. The name huck_finn_chapters is currently bound to a list of all the chapters in the book. We can place those chapters into a table to see how each begins.
Table([huck_finn_chapters], ['Chapters'])
Each chapter begins with a chapter number in Roman numerals. That is followed by the first sentence of the chapter. Project Gutenberg has printed the first word of each chapter in upper case.
The book describes a journey that Huck and Jim take along the Mississippi River. Tom Sawyer joins them towards the end as the action heats up. We can quickly visualize how many times these characters have each been mentioned at any point in the book.
counts = Table([np.char.count(huck_finn_chapters, "Jim"),
np.char.count(huck_finn_chapters, "Tom"),
np.char.count(huck_finn_chapters, "Huck")],
["Jim", "Tom", "Huck"])
counts.cumsum().plot(overlay=True)

In the plot above, the horizontal axis shows chapter numbers and the vertical axis shows how many times each character has been mentioned so far. You can see that Jim is a central character, by the large number of times his name appears. Notice how Tom is hardly mentioned for much of the book until after Chapter 30. His curve and Jim's rise sharply at that point, as the action involving both of them intensifies. As for Huck, his name hardly appears at all, because he is the narrator.
Little Women is a story of four sisters growing up together during the civil war. In this book, chapter numbers are spelled out and chapter titles are written in all capital letters.
Table({'Chapters': little_women_chapters})
We can track the mentions of main characters to learn about the plot of this book as well. The protagonist Jo interacts with her sisters Meg, Beth, and Amy regularly, up until Chapter 27 when she moves to New York alone.
people = ["Meg", "Jo", "Beth", "Amy", "Laurie"]
people_counts = Table({pp: np.char.count(little_women_chapters, pp) for pp in people})
people_counts.cumsum().plot(overlay=True)

Laurie is a young man who marries one of the girls in the end. See if you can use the plots to guess which one.
Investigating data using visualizations, such as these cumulative count plots, is the central theme of Chapter 2 of this text. One of the central goals of this text is to provide you with the tools to visualize a wide range of data — numbers, text, and structures — while learning to interpret the resulting images.
Chapter 3 investigates the problem of determining whether two similar patterns are really the same or different. For example, in the context of novels, the word "character" has a second meaning: a printed symbol such as a letter or number. Below, we compare the counts of this type of character in the first chapter of Little Women.
from collections import Counter
chapter_one = little_women_chapters[0]
counts = Counter(chapter_one.lower())
letters = Table([counts.keys(), counts.values()], ['Letters', 'Chapter 1 Count'])
letters.sort('Letters').show(20)
How do these counts compare with the character counts in Chapter 2? By plotting both sets of counts in one chart, we can see slight variations for every character. Is that difference meaningful? These questions will be addressed precisely in this text.
counts = Counter(little_women_chapters[1].lower())
two_letters = Table([counts.keys(), counts.values()], ['Letters', 'Chapter 2 Count'])
compare = letters.join('Letters', two_letters)
compare.barh('Letters', overlay=True)

In this text, we will learn to describe the relationships between quantities and use that information to make predictions. First, we will explore how to make accurate predictions based on incomplete information. Later, we will develop methods that will allow us to integrate multiple sources of uncertain information to make decisions.
As an example, let us first use the computer to get us some information that would be really tedious to acquire by hand: the number of characters and the number of periods in each chapter of both books.
chlen_per_hf = Table([[len(s) for s in huck_finn_chapters],
np.char.count(huck_finn_chapters, '.')],
["HF Chapter Length", "Number of periods"])
chlen_per_lw = Table([[len(s) for s in little_women_chapters],
np.char.count(little_women_chapters, '.')],
["LW Chapter Length", "Number of periods"])
Here are the data for Huckleberry Finn. Each row of the table below corresponds to one chapter of the novel, and displays the number of characters as well as the number of periods in the chapter. Not surprisingly, chapters with fewer characters also tend to have fewer periods, in general; the shorter the chapter, the fewer sentences there tend to be, and vice versa. The relation is not entirely predictable, however, as sentences are of varying lengths and can involve other punctuation such as question marks.
chlen_per_hf
Here are the corresponding data for Little Women.
chlen_per_lw
You can see that the chapters of Little Women are in general longer than those of Huckleberry Finn. Let us see if these two simple variables – the length and number of periods in each chapter – can tell us anything more about the two authors. One way for us to do this is to plot both sets of data on the same axes.
In the plot below, there is a dot for each chapter in each book. Blue dots correspond to Huckleberry Finn and yellow dots to Little Women. The horizontal axis represents the number of characters and the vertical axis represents the number of periods.
plots.figure(figsize=(10,10))
plots.scatter([len(s) for s in huck_finn_chapters], np.char.count(huck_finn_chapters, '.'), color='b')
plots.scatter([len(s) for s in little_women_chapters], np.char.count(little_women_chapters, '.'), color='y')

The plot shows us that many but not all of the chapters of Little Women are longer than those of Huckleberry Finn, as we had observed by just looking at the numbers. But it also shows us something more. Notice how the blue points are roughly clustered around a straight line, as are the yellow points. Moreover, it looks as though both colors of points might be clustered around the same straight line.
Indeed, a "rough and ready" conclusion from looking at the plot would be that on average both books tend to have somewhere between 100 and 150 characters between periods. Thus their sentence lengths might be comparable even though the chapter lengths are not. We will revisit this example later in the course to see if this rough conclusion is justified. In the meanwhile, you might want to think about whether the two great 19th century novels of our example were signaling something so very familiar us now: the 140-character limit of Twitter.
Causality and Experiments
"These problems are, and will probably ever remain, among the inscrutable secrets of nature. They belong to a class of questions radically inaccessible to the human intelligence." —The Times of London, September 1849, on how cholera is contracted and spread
Does the death penalty have a deterrent effect? Is chocolate good for you? What causes breast cancer?
All of these questions attempt to assign a cause to an effect. A careful examination of data can help shed light on questions like these. In this section you will learn some of the fundamental concepts involved in establishing causality.
Observation is a key to good science. An observational study is one in which scientists make conclusions based on data that they have observed but had no hand in generating. In data science, many such studies involve observations on a group of individuals, a factor of interest called a treatment, and an outcome measured on each individual.
It is easiest to think of the individuals as people. In a study of whether chocolate is good for the health, the individuals would indeed be people, the treatment would be eating chocolate, and the outcome might be a measure of blood pressure. But individuals in observational studies need not be people. In a study of whether the death penalty has a deterrent effect, the individuals could be the 50 states of the union. A state law allowing the death penalty would be the treatment, and an outcome could be the state’s murder rate.
The fundamental question is whether the treatment has an effect on the outcome. Any relation between the treatment and the outcome is called an association. If the treatment causes the outcome to occur, then the association is causal. Causality is at the heart of all three questions posed at the start of this section. For example, one of the questions was whether chocolate directly causes improvements in health, not just whether there there is a relation between chocolate and health.
The establishment of causality often takes place in two stages. First, an association is observed. Next, a more careful analysis leads to a decision about causality.
Observation and Visualization: John Snow and the Broad Street Pump
One of the earliest examples of astute observation eventually leading to the establishment of causality dates back more than 150 years. To get your mind into the right timeframe, try to imagine London in the 1850’s. It was the world’s wealthiest city but many of its people were desperately poor. Charles Dickens, then at the height of his fame, was writing about their plight. Disease was rife in the poorer parts of the city, and cholera was among the most feared. It was not yet known that germs cause disease; the leading theory was that “miasmas” were the main culprit. Miasmas manifested themselves as bad smells, and were thought to be invisible poisonous particles arising out of decaying matter. Parts of London did smell very bad, especially in hot weather. To protect themselves against infection, those who could afford to held sweet-smelling things to their noses.
For several years, a doctor by the name of John Snow had been following the devastating waves of cholera that hit England from time to time. The disease arrived suddenly and was almost immediately deadly: people died within a day or two of contracting it, hundreds could die in a week, and the total death toll in a single wave could reach tens of thousands. Snow was skeptical of the miasma theory. He had noticed that while entire households were wiped out by cholera, the people in neighboring houses sometimes remained completely unaffected. As they were breathing the same air—and miasmas—as their neighbors, there was no compelling association between bad smells and the incidence of cholera.
Snow had also noticed that the onset of the disease almost always involved vomiting and diarrhea. He therefore believed that that infection was carried by something people ate or drank, not by the air that they breathed. His prime suspect was water contaminated by sewage.
At the end of August 1854, cholera struck in the overcrowded Soho district of London. As the deaths mounted, Snow recorded them diligently, using a method that went on to become standard in the study of how diseases spread: he drew a map. On a street map of the district, he recorded the location of each death.
Here is Snow’s original map. Each black bar represents one death. The black discs mark the locations of water pumps. The map displays a striking revelation–the deaths are roughly clustered around the Broad Street pump.
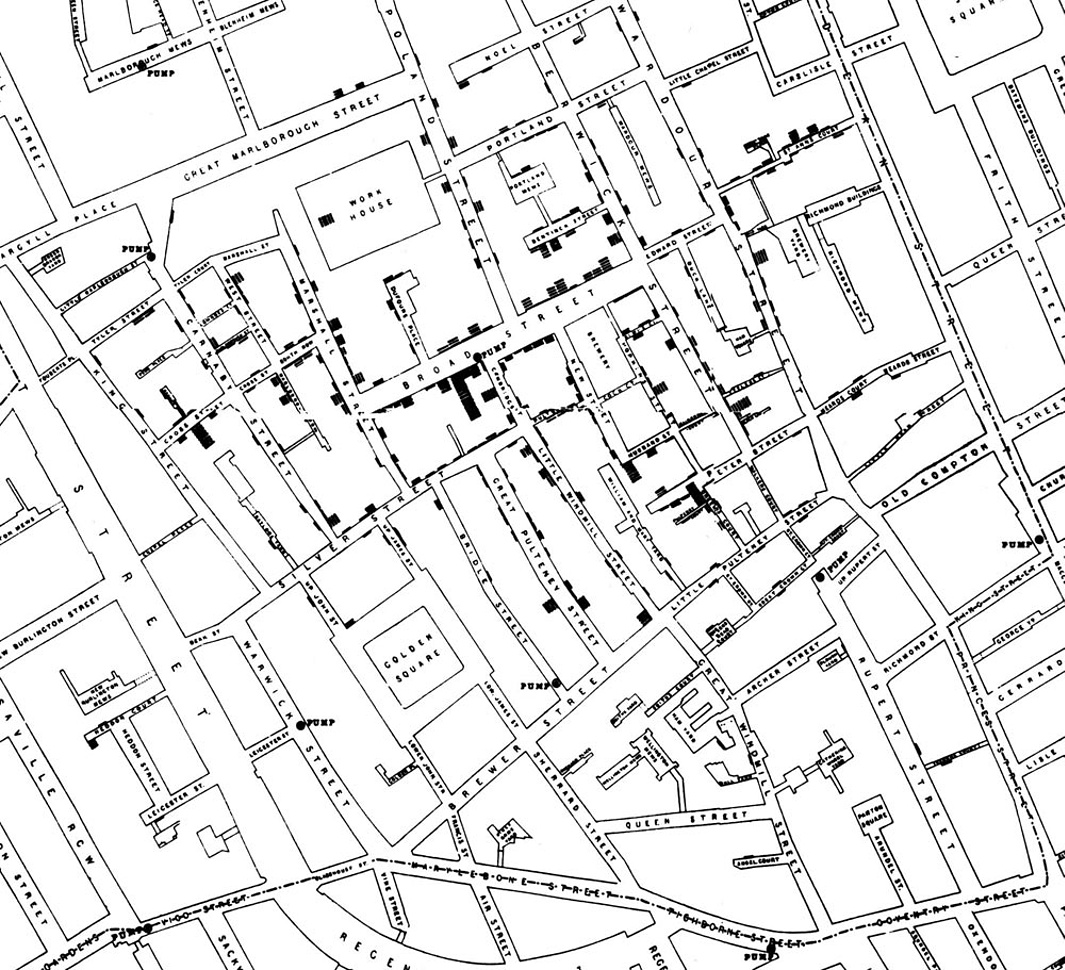
Snow studied his map carefully and investigated the apparent anomalies. All of them implicated the Broad Street pump. For example:
- There were deaths in houses that were nearer the Rupert Street pump than the Broad Street pump. Though the Rupert Street pump was closer as the crow flies, it was less convenient to get to because of dead ends and the layout of the streets. The residents in those houses used the Broad Street pump instead.
- There were no deaths in two blocks just east of the pump. That was the location of the Lion Brewery, where the workers drank what they brewed. If they wanted water, the brewery had its own well.
- There were scattered deaths in houses several blocks away from the Broad Street pump. Those were children who drank from the Broad Street pump on their way to school. The pump’s water was known to be cool and refreshing.
The final piece of evidence in support of Snow’s theory was provided by two isolated deaths in the leafy and genteel Hampstead area, quite far from Soho. Snow was puzzled by these until he learned that the deceased were Mrs. Susannah Eley, who had once lived in Broad Street, and her niece. Mrs. Eley had water from the Broad Street pump delivered to her in Hampstead every day. She liked its taste.
Later it was discovered that a cesspit that was just a few feet away from the well of the Broad Street pump had been leaking into the well. Thus the pump’s water was contaminated by sewage from the houses of cholera victims.
Snow used his map to convince local authorities to remove the handle of the Broad Street pump. Though the cholera epidemic was already on the wane when he did so, it is possible that the disabling of the pump prevented many deaths from future waves of the disease.
The removal of the Broad Street pump handle has become the stuff of legend. At the Centers for Disease Control (CDC) in Atlanta, when scientists look for simple answers to questions about epidemics, they sometimes ask each other, “Where is the handle to this pump?”
Snow’s map is one of the earliest and most powerful uses of data visualization. Disease maps of various kinds are now a standard tool for tracking epidemics.
Towards Causality
Though the map gave Snow a strong indication that the cleanliness of the water supply was the key to controlling cholera, he was still a long way from a convincing scientific argument that contaminated water was causing the spread of the disease. To make a more compelling case, he had to use the method of comparison.
Scientists use comparison to identify an association between a treatment and an outcome. They compare the outcomes of a group of individuals who got the treatment (the treatment group) to the outcomes of a group who did not (the control group). For example, researchers today might compare the average murder rate in states that have the death penalty with the average murder rate in states that don’t.
If the results are different, that is evidence for an association. To determine causation, however, even more care is needed.
Snow’s “Grand Experiment”
Encouraged by what he had learned in Soho, Snow completed a more thorough analysis of cholera deaths. For some time, he had been gathering data on cholera deaths in an area of London that was served by two water companies. The Lambeth water company drew its water upriver from where sewage was discharged into the River Thames. Its water was relatively clean. But the Southwark and Vauxhall (S&V) company drew its water below the sewage discharge, and thus its supply was contaminated.
Snow noticed that there was no systematic difference between the people who were supplied by S&V and those supplied by Lambeth. “Each company supplies both rich and poor, both large houses and small; there is no difference either in the condition or occupation of the persons receiving the water of the different Companies … there is no difference whatever in the houses or the people receiving the supply of the two Water Companies, or in any of the physical conditions with which they are surrounded …”
The only difference was in the water supply, “one group being supplied with water containing the sewage of London, and amongst it, whatever might have come from the cholera patients, the other group having water quite free from impurity.”
Confident that he would be able to arrive at a clear conclusion, Snow summarized his data in the table below.
| Supply Area | Number of houses | cholera deaths | deaths per 10,000 houses |
|---|---|---|---|
| S&V | 40,046 | 1,263 | 315 |
| Lambeth | 26,107 | 98 | 37 |
| Rest of London | 256,423 | 1,422 | 59 |
The numbers pointed accusingly at S&V. The death rate from cholera in the S&V houses was almost ten times the rate in the houses supplied by Lambeth.
Establishing Causality
In the language developed earlier in the section, you can think of the people in the S&V houses as the treatment group, and those in the Lambeth houses at the control group. A crucial element in Snow’s analysis was that the people in the two groups were comparable to each other, apart from the treatment.
In order to establish whether it was the water supply that was causing cholera, Snow had to compare two groups that were similar to each other in all but one aspect–their water supply. Only then would he be able to ascribe the differences in their outcomes to the water supply. If the two groups had been different in some other way as well, it would have been difficult to point the finger at the water supply as the source of the disease. For example, if the treatment group consisted of factory workers and the control group did not, then differences between the outcomes in the two groups could have been due to the water supply, or to factory work, or both, or to any other characteristic that made the groups different from each other. The final picture would have been much more fuzzy.
Snow’s brilliance lay in identifying two groups that would make his comparison clear. He had set out to establish a causal relation between contaminated water and cholera infection, and to a great extent he succeeded, even though the miasmatists ignored and even ridiculed him. Of course, Snow did not understand the detailed mechanism by which humans contract cholera. That discovery was made in 1883, when the German scientist Robert Koch isolated the Vibrio cholerae, the bacterium that enters the human small intestine and causes cholera.
In fact the Vibrio cholerae had been identified in 1854 by Filippo Pacini in Italy, just about when Snow was analyzing his data in London. Because of the dominance of the miasmatists in Italy, Pacini’s discovery languished unknown. But by the end of the 1800’s, the miasma brigade was in retreat. Subsequent history has vindicated Pacini and John Snow. Snow’s methods led to the development of the field of epidemiology, which is the study of the spread of diseases.
Confounding
Let us now return to more modern times, armed with an important lesson that we have learned along the way:
In an observational study, if the treatment and control groups differ in ways other than the treatment, it is difficult to make conclusions about causality.
An underlying difference between the two groups (other than the treatment) is called a confounding factor, because it might confound you (that is, mess you up) when you try to reach a conclusion.
Example: Coffee and lung cancer. Studies in the 1960’s showed that coffee drinkers had higher rates of lung cancer than those who did not drink coffee. Because of this, some people identified coffee as a cause of lung cancer. But coffee does not cause lung cancer. The analysis contained a confounding factor – smoking. In those days, coffee drinkers were also likely to have been smokers, and smoking does cause lung cancer. Coffee drinking was associated with lung cancer, but it did not cause the disease.
Confounding factors are common in observational studies. Good studies take great care to reduce confounding.
Randomization
An excellent way to avoid confounding is to assign individuals to the treatment and control groups at random, and then administer the treatment to those who were assigned to the treatment group. Randomization keeps the two groups similar apart from the treatment.
If you are able to randomize individuals into the treatment and control groups, you are running a randomized controlled experiment, also known as a randomized controlled trial (RCT). Sometimes, people’s responses in an experiment are influenced by their knowing which group they are in. So you might want to run a blind experiment in which individuals do not know whether they are in the treatment group or the control group. To make this work, you will have to give the control group a placebo, which is something that looks exactly like the treatment but in fact has no effect.
Randomized controlled experiments have long been a gold standard in the medical field, for example in establishing whether a new drug works. They are also becoming more commonly used in other fields such as economics.
Example: Welfare subsidies in Mexico. In Mexican villages in the 1990’s, children in poor families were often not enrolled in school. One of the reasons was that the older children could go to work and thus help support the family. Santiago Levy , a minister in Mexican Ministry of Finance, set out to investigate whether welfare programs could be used to increase school enrollment and improve health conditions. He conducted an RCT on a set of villages, selecting some of them at random to receive a new welfare program called PROGRESA. The program gave money to poor families if their children went to school regularly and the family used preventive health care. More money was given if the children were in secondary school than in primary school, to compensate for the children’s lost wages, and more money was given for girls attending school than for boys. The remaining villages did not get this treatment, and formed the control group. Because of the randomization, there were no confounding factors and it was possible to establish that PROGRESA increased school enrollment. For boys, the enrollment increased from 73% in the control group to 77% in the PROGRESA group. For girls, the increase was even greater, from 67% in the control group to almost 75% in the PROGRESA group. Due to the success of this experiment, the Mexican government supported the program under the new name OPORTUNIDADES, as an investment in a healthy and well educated population.
In some situations it might not be possible to carry out a randomized controlled experiment, even when the aim is to investigate causality. For example, suppose you want to study the effects of alcohol consumption during pregnancy, and you randomly assign some pregnant women to your “alcohol” group. You should not expect cooperation from them if you present them with a drink. In such situations you will almost invariably be conducting an observational study, not an experiment. Be alert for confounding factors.
Endnote
In the terminology of that we have developed, John Snow conducted an observational study, not a randomized experiment. But he called his study a “grand experiment” because, as he wrote, “No fewer than three hundred thousand people … were divided into two groups without their choice, and in most cases, without their knowledge …”
Studies such as Snow’s are sometimes called “natural experiments.” However, true randomization does not simply mean that the treatment and control groups are selected “without their choice.”
The method of randomization can be as simple as tossing a coin. It may also be quite a bit more complex. But every method of randomization consists of a sequence of carefully defined steps that allow chances to be specified mathematically. This has two important consequences.
- It allows us to account–mathematically–for the possibility that randomization produces treatment and control groups that are quite different from each other.
- It allows us to make precise mathematical statements about differences between the treatment and control groups. This in turn helps us make justifiable conclusions about whether the treatment has any effect.
In this course, you will learn how to conduct and analyze your own randomized experiments. That will involve more detail than has been presented in this section. For now, just focus on the main idea: to try to establish causality, run a randomized controlled experiment if possible. If you are conducting an observational study, you might be able to establish association but not causation. Be extremely careful about confounding factors before making conclusions about causality based on an observational study.
Terminology
- observational study
- treatment
- outcome
- association
- causal association
- causality
- comparison
- treatment group
- control group
- epidemiology
- confounding
- randomization
- randomized controlled experiment
- randomized controlled trial (RCT)
- blind
- placebo
Fun facts
- John Snow is sometimes called the father of epidemiology, but he was an anesthesiologist by profession. One of his patients was Queen Victoria, who was an early recipient of anesthetics during childbirth.
- Florence Nightingale, the originator of modern nursing practices and famous for her work in the Crimean War, was a die-hard miasmatist. She had no time for theories about contagion and germs, and was not one for mincing her words. “There is no end to the absurdities connected with this doctrine,” she said. “Suffice it to say that in the ordinary sense of the word, there is no proof such as would be admitted in any scientific enquiry that there is any such thing as contagion.”
- A later RCT established that the conditions on which PROGRESA insisted – children going to school, preventive health care – were not necessary to achieve increased enrollment. Just the financial boost of the welfare payments was sufficient.
Good reads
The Strange Case of the Broad Street Pump: John Snow and the Mystery of Cholera by Sandra Hempel, published by our own University of California Press, reads like a whodunit. It was one of the main sources for this section's account of John Snow and his work. A word of warning: some of the contents of the book are stomach-churning.
Poor Economics, the best seller by Abhijit V. Banerjee and Esther Duflo of MIT, is an accessible and lively account of ways to fight global poverty. It includes numerous examples of RCTs, including the PROGRESA example in this section.
Expressions
Programming can dramatically improve our ability to collect and analyze information about the world, which in turn can lead to discoveries through the kind of careful reasoning demonstrated in the previous section. In data science, the purpose of writing a program is to instruct a computer to carry out the steps of an analysis. Computers cannot study the world on their own. People must describe precisely what steps the computer should take in order to collect and analyze data, and those steps are expressed through programs.
To learn to program, we will begin by learning some of the grammar rules of a programming language. Programs are made up of expressions, which describe to the computer how to combine pieces of data. For example, a multiplication expression consists of a * symbol between two numerical expressions. Expressions, such as 3 * 4, are evaluated by the computer. The value (the result of evaluation) of the last expression in each cell, 12 in this case, is displayed below the cell.
3 * 4
The rules of a programming language are rigid. In Python, the * symbol cannot appear twice in a row. The computer will not try to interpret an expression that differs from its prescribed expression structures. Instead, it will show a SyntaxError error. The Syntax of a language is its set of grammar rules, and a SyntaxError indicates that some rule has been violated.
3 * * 4
Small changes to an expression can change its meaning entirely. Below, the space between the *'s has been removed. Because ** appears between two numerical expressions, the expression is a well-formed exponentiation expression (the first number raised to the power of the second: 3 times 3 times 3 times 3). The symbols * and ** are called operators, and the values they combine are called operands.
3 ** 4
Common Operators. Data science often involves combining numerical values, and the set of operators in a programming language are designed to so that expressions can be used to express any sort of arithmetic. In Python, the following operators are essential.
| Expression Type | Operator | Example | Value |
|---|---|---|---|
| Addition | + |
2 + 3 |
5 |
| Subtraction | - |
2 - 3 |
-1 |
| Multiplication | * |
2 * 3 |
6 |
| Division | / |
7 / 3 |
2.66667 |
| Remainder | % |
7 % 3 |
1 |
| Exponentiation | ** |
2 ** 0.5 |
1.41421 |
Python expressions obey the same familiar rules of precedence as in algebra: multiplication and division occur before addition and subtraction. Parentheses can be used to group together smaller expressions within a larger expression.
1 * 2 * 3 * 4 * 5 / 6 ** 3 + 7 + 8
1 * 2 * ((3 * 4 * 5 / 6) ** 3) + 7 + 8
This chapter introduces many types of expressions. Learning to program involves trying out everything you learn in combination, investigating the behavior of the computer. What happens if you divide by zero? What happens if you divide twice in a row? You don't always need to ask an expert (or the Internet); many of these details can be discovered by trying them out yourself.
Names
Names are given to values in Python using an assignment expression. In an assignment, a name is followed by =, which is followed by another expression. The value of the expression to the right of = is assigned to the name. Once a name has a value assigned to it, the value will be substituted for that name in future expressions.
a = 10
b = 20
a + b
A previously assigned name can be used in the expression to the right of =.
quarter = 2
whole = 4 * quarter
whole
However, only the current value of an expression is assiged to a name. If that value changes later, names that were defined in terms of that value will not change automatically.
quarter = 4
whole
Names must start with a letter, but can contain both letters and numbers. A name cannot contain a space; instead, it is common to use an underscore character _ to replace each space. Names are only as useful as you make them; it's up to the programmer to choose names that are easy to interpret. Typically, more meaningful names can be invented than a and b. For example, to describe the sales tax on a $5 purchase in Berkeley, CA, the following names clarify the meaning of the various quantities involved.
purchase_price = 5
state_tax_rate = 0.075
county_tax_rate = 0.02
city_tax_rate = 0
sales_tax_rate = state_tax_rate + county_tax_rate + city_tax_rate
sales_tax = purchase_price * sales_tax_rate
sales_tax
Example: Growth Rates
The relationship between two comparable numbers is often expressed as a growth rate. For example, the United States federal government employed 2,766,000 people in 2002 and 2,814,000 people in 2012
http://www.bls.gov/opub/mlr/2013/article/industry-employment-and-output-projections-to-2022-1.htm
. To compute a growth rate, we must first decide which value to treat as the initial amount. For values over time, the earlier value is a natural choice. Then, we divide the difference between the changed and initial amount by the initial amount.
initial = 2766000
changed = 2814000
(changed - initial) / initial
A useful property of growth rates is that they don't change even if the values are expressed in different units. So, for example, we can express the same relationship between thousands of people in 2002 and 2012.
initial = 2766
changed = 2814
(changed - initial) / initial
In 10 years, the number of employees of the US Federal Government has increased by only 1.74%. In that time, the total expenditures of the US Federal Government increased from \$2.37 trillion to \$3.38 trillion in 2012.
initial = 2.37
changed = 3.38
(changed - initial) / initial
A 42.6% increase in the federal budget is much larger than the 1.74% increase in federal employees. In fact, the number of federal employees has grown much more slowly than the population of the United States, which increased 9.21% from 287.6 million people in 2002 to 314.1 million in 2012.
initial = 287.6
changed = 314.1
(changed - initial) / initial
A growth rate can be negative, representing a decrease in some value. For example, the number of manufacturing jobs in the US decreased from 15.3 million in 2002 to 11.9 million in 2012, a -22.2% growth rate.
initial = 15.3
changed = 11.9
(changed - initial) / initial
Call Expressions
Call expressions invoke functions, which are named operations. The name of the function appears first, followed by expressions in parentheses.
abs(-12)
round(5 - 1.3)
max(2, 2 + 3, 4)
In this last example, the max function is called on three arguments: 2, 5, and 4. The value of each expression within parentheses is passed to the function, and the function returns the final value of the full call expression. The max function can take any number of arguments and returns the maximum.
A few functions are available by default, such as abs and round, but most functions that are built into the Python language are stored in a collection of functions called a module. An import statement is used to provide access to a module, such as math or operator.
import math
import operator
math.sqrt(operator.add(4, 5))
An equivalent expression could be expressed using the + and ** operators instead.
(4 + 5) ** 0.5
Operators and call expressions can be used together in an expression. The percent difference between two values is used to compare values for which neither one is obviously initial or changed. For example, in 2014 Florida farms produced 2.72 billion eggs while Iowa farms produced 16.25 billion eggs
http://quickstats.nass.usda.gov/
. The percent difference is 100 times the absolute value of the difference between the values, divided by their average. In this case, the difference is larger than the average, and so the percent difference is greater than 100.
florida = 2.72
iowa = 16.25
100*abs(florida-iowa)/((florida+iowa)/2)
Learning how different functions behave is an important part of learning a programming language. A Jupyter notebook can assist in remembering the names and effects of different functions. When editing a code cell, press the tab key after typing the beginning of a name to bring up a list of ways to complete that name. For example, press tab after math. to see all of the functions available in the math module. Typing will narrow down the list of options. To learn more about a function, place a ? after its name. For example, typing math.log? will bring up a description of the log function in the math module.
math.log?
log(x[, base])
Return the logarithm of x to the given base.
If the base not specified, returns the natural logarithm (base e) of x.The square brackets in the example call indicate that an argument is optional. That is, log can be called with either one or two arguments.
math.log(16, 2)
math.log(16)/math.log(2)
Data Types
Python includes several types of values that will allow us to compute about more than just numbers.
| Type Name | Python Class | Example 1 | Example 2 |
|---|---|---|---|
| Integer | int |
1 |
-2 |
| Floating-Point Number | float |
1.5 |
-2.0 |
| Boolean | bool |
True |
False |
| String | str |
'hello world' |
"False" |
The first two types represent numbers. A "floating-point" number describes its representation by a computer, which is a topic for another text. Practically, the difference between an integer and a floating-point number is that the latter can represent fractions in addition to whole values.
Boolean values, named for the logician George Boole, represent truth and take only two possible values: True and False.
Strings are the most flexible type of all. They can contain arbitrary text. A string can describe a number or a truth value, as well as any word or sentence. Much of the world's data is text, and text is represented in computers as strings.
The meaning of an expression depends both upon its structure and the types of values that are being combined. So, for instance, adding two strings together produces another string. This expression is still an addition expression, but it is combining a different type of value.
"data" + "science"
Addition is completely literal; it combines these two strings together without regard for their contents. It doesn't add a space because these are different words; that's up to the programmer (you) to specify.
"data" + " sc" + "ienc" + "e"
Single and double quotes can both be used to create strings: 'hi' and "hi" are identical expressions. Double quotes are often preferred because they allow you to include apostrophes inside of strings.
"This won't work with a single-quoted string!"
Why not? Try it out.
The str function returns a string representation of any value.
str(2 + 3) + ' ' + str(True)
There are also functions to transform strings that begin with str., such as str.upper to create an upper-case string.
str.upper("That's " + str(False)) + '!'
Comparisons
Boolean values most often arise from comparison operators. Python includes a variety of operators that compare values. For example, 3 is larger than 1 + 1.
3 > 1 + 1
The value True indicates that the comparison is valid; Python has confirmed this simple fact about the relationship between 3 and 1+1. The full set of common comparison operators are listed below.
| Comparison | Operator | True example | False Example |
|---|---|---|---|
| Less than | < | 2 < 3 | 2 < 2 |
| Greater than | > | 3>2 | 3>3 |
| Less than or equal | <= | 2 <= 2 | 3 <= 2 |
| Greater or equal | >= | 3 >= 3 | 2 >= 3 |
| Equal | == | 3 == 3 | 3 == 2 |
| Not equal | != | 3 != 2 | 2 != 2 |
An expression can contain multiple comparisons, and they all must hold in order for the whole expression to be True. For example, we can express that 1+1 is between 1 and 3 using the following expression.
1 < 1 + 1 < 3
The average of two numbers is always between the smaller number and the larger number. We express this relationship for the numbers x and y below. You can try different values of x and y to confirm this relationship.
x = 12
y = 5
min(x, y) <= (x+y)/2 <= max(x, y)
Strings can also be compared, and their order is alphabetical. A shorter string is less than a longer string that begins with the shorter string.
"Dog" > "Catastrophe" > "Cat"
Collections
Values can be grouped together into collections, which allows programmers to organize those values and refer to all of them with a single name. The most common way to group together values is by placing them in a list, which is expessed by separating elements using commas within square brackets. After a comma, it's okay to start a new line. Below, we collect four different years and the corresponding average world temperature over land (in degrees Celsius) in the decade leading up to each year.
http://berkeleyearth.lbl.gov/regions/global-land
years = [1850, 1900,
1950, 2000]
temps = [8.1, 8.3, 8.7, 9.4]
The elements of these lists can be accessed within expressions, also using square brackets. Each element has an index, starting at 0. Once accessed, these values can be placed into other lists. The expression below gives us a list of the growth rates for each 50 year period. Not only is the world land temperature increasing, but its growth rate is increasing as well.
[(temps[1]-temps[0])/temps[0],
(temps[2]-temps[1])/temps[1],
(temps[3]-temps[2])/temps[2]]
Tuples. Values can also be grouped together into tuples in addition to lists. A tuple is expressed by separating elements using commas within parentheses: (1, 2, 3). In many cases, lists and tuples are interchangeable.
Arrays
Many experiments and data sets involve multiple values of the same type. An array is a collection of values that all have the same type. The numpy package, abbreviated np in programs, provides Python programmers with convenient and powerful functions for creating and manipulating arrays.
An array is created using the np.array function, which takes a list or tuple as an argument.
temps = np.array([8.1, 8.3, 8.7, 9.4])
temps
Arrays differ from lists and tuples because they can be used in arithmetic expressions to compute over their contents. When two arrays are combined together using an arithmetic operator, their individual values are combined.
temps + temps
When an array is combined with a single number, that number is combined with each element of the array.
temps - temps[0]
Arrays also have methods, which are functions that operate on the array values. The mean of a collection of numbers is its average value: the sum divided by the length. Each pair of parentheses in the example below is part of a call expression; it's calling a function with no arguments to perform a computation on the array called temps.
temps.size, temps.sum(), temps.mean()
It's common that small rounding errors appear in arithmetic on a computer. For instance, if we compute the maximum value in temps using the max method, the result is a number very near (but not exactly) 9.4. Arithmetic rounding errors are an important topic in scientific computing, but won't be a focus of this text. Everyone who works with data must be aware that some operations will be approximated so that values can be stored and manipulated efficiently.
temps.max()
Functions on Arrays¶
In addition to basic arithmetic and methods such as min and max, manipulating arrays often involves calling functions that are part of the np package. For example, the diff function computes the difference between each adjacent pair of elements in an array. The first element of the diff is the second element minus the first.
np.diff(temps)
The full Numpy reference lists these functions exhaustively, but only a small subset are used commonly for data processing applications. These are grouped into different packages within np. Learning this vocabulary is an important part of learning the Python language, so refer back to this list often as you work through examples and problems.
Each of these functions takes an array as an argument and returns a single value.
| Function | Description |
|---|---|
np.prod |
Multiply all elements together |
np.sum |
Add all elements together |
np.all |
Test whether all elements are true values (non-zero numbers are true) |
np.any |
Test whether any elements are true values (non-zero numbers are true) |
np.count_nonzero |
Count the number of non-zero elements |
Each of these functions takes an array as an argument and returns an array of values.
| Function | Description |
|---|---|
np.diff |
Difference between adjacent elements |
np.round |
Round each number to the nearest integer (whole number) |
np.cumprod |
A cumulative product: for each element, multiply all elements so far |
np.cumsum |
A cumulative sum: for each element, add all elements so far |
np.exp |
Exponentiate each element |
np.log |
Take the natural logarithm of each element |
np.sqrt |
Take the square root of each element |
np.sort |
Sort the elements |
Each of these functions takes an array of strings and returns an array.
| Function | Description |
|---|---|
np.char.lower |
Lowercase each element |
np.char.upper |
Uppercase each element |
np.char.strip |
Remove spaces at the beginning or end of each element |
np.char.isalpha |
Whether each element is only letters (no numbers or symbols) |
np.char.isnumeric |
Whether each element is only numeric (no letters) |
Each of these functions takes both an array of strings and a search string; each returns an array.
| Function | Description |
|---|---|
np.char.count |
Count the number of times a search string appears among the elements of an array |
np.char.find |
The position within each element that a search string is found first |
np.char.rfind |
The position within each element that a search string is found last |
np.char.startswith |
Whether each element starts with the search string |
Tables
Tables¶
Tables are a fundamental object type for representing data sets. A table can be viewed in two ways. Tables are a sequence of named columns that each describe a single aspect of all entries in a data set. Tables are also a sequence of rows that each contain all information about a single entry in a data set.
Tables are typically created from files that contain comma-separated values, called CSV files. The file below contains "Annual Estimates of the Resident Population by Single Year of Age and Sex for the United States."
census_url = 'http://www.census.gov/popest/data/national/asrh/2014/files/NC-EST2014-AGESEX-RES.csv'
full_table = Table.read_table(census_url)
full_table
A description of the table appears online. The SEX column contains numeric codes: 0 stands for the total, 1 for male, and 2 for female. The AGE column contains ages, but the special value 999 is a sum of the total population. The rest of the columns contain estimates of the US population.
Typically, a public table will contain more information than necessary for a particular investigation or analysis. In this case, let us suppose that we are only interested in the population changes from 2010 to 2014. We can select only a subset of the columns using the select method.
census = full_table.select(['SEX', 'AGE', 'POPESTIMATE2010', 'POPESTIMATE2014'])
census
The names used for columns in the original table can be changed, often to clarify or simplify future computations. Be careful, the relabel method does alter the table, so that the original name is lost.
census.relabel('POPESTIMATE2010', '2010')
census.relabel('POPESTIMATE2014', '2014')
census
Each column of a table is an array of the same length, and so columns can be combined. Columns are accessed and assigned by name using square brackets.
census['Change'] = census['2014'] - census['2010']
census['Growth'] = census['Change'] / census['2010']
census
Although the columns of this table are simply arrays of numbers, the format of those numbers can be changed to improve the interpretability of the table. The set_format method takes Formatter objects, which exist for dates (DateFormatter), currencies (CurrencyFormatter), numbers, and percentages.
census.set_format('Growth', PercentFormatter)
census.set_format(['2010', '2014', 'Change'], NumberFormatter)
census
The information in a table can be accessed in many ways. The attributes column_labels, columns, and rows demonstrated below are used for any table.
census.column_labels
len(census)
len(census.rows)
census.rows[0]
census.columns[2]
census.rows[0][2]
census.columns[2][0]
Let's take a look at the growth rates of the total number of males and females by selecting only the rows that sum over all ages. This sum is expressed with the special value 999 according to this data set description.
census.where('AGE', 999)
What ages of males are driving this rapid growth? We can first filter the census table to keep only the male entries, then sort by growth rate in decreasing order.
males = census.where('SEX', 1)
males.sort('Growth', descending=True)
The fact that there are more men with AGE of 100 than 99 looks suspicious; shouldn't there be fewer? A careful look at the description of the data set reveals that the 100 category actually includes all men who are 100 or older. The growth rates in men at these very old ages could have several explanations, such as a large influx from another country, but the most natural explanation is that people are simply living longer in 2014 than 2010.
The where method can also take an array of boolean values, constructed by applying some comparison operator to a column of the table. For example, we can find all of the age groups among both sexes for which the absolute Change is substantial. The show method displays all rows without abbreviating.
both = census.where(census['SEX'] != 0)
both.where(both['Change'] > 200000).sort('AGE').show()
Many of the same ages appear for both males (1) and females (2), and most are clumped together in the 57-67 range. In 2014, these people would be born between 1947 and 1957, the height of the post-WWII baby boom in the United States.
It is possible to specify multiple conditions using the functions np.logical_and and np.logical_or. When two conditions are combined with logical_and, both must be true for a row to be retained. When conditions are combined with logical_or, then either one of them must be true for a row to be retained. Here are two different ways to select 18 and 19 year olds.
both.where(np.logical_or(both['AGE']==18, both['AGE']==19))
both.where(np.logical_and(both['AGE']>=18, both['AGE']<=19))
Here, we observe a rather dramatic decrease in the number of 18 and 19 year olds in the United States; the children of the baby boom are now even older.
Aggregation and Grouping. This particular dataset includes entries for sums across all ages and sexes, using the special values 999 and 0 respectively. However, if these rows did not exist, we would be able to aggregate the remaining entries.
no_sums = both.select(['SEX', 'AGE', '2014']).where(both['AGE'] != 999)
females = no_sums.where('SEX', 2).select(['AGE', '2014'])
sum(females['2014'])
Some columns express categories, such as the sex or age group in the case of the census table. Aggregation can also be performed on every value for a category using the group and groups methods. The group method takes a single column (or column name) as an argument and collects all values associated with each unique value in that column.
no_sums.group('AGE')
A second argument, the name of a function, can be provided to group in order to aggregate the resulting values. For exmaple, the sum function can be used to add together the populations for each age. In this result, the SEX sum column is meaningless because the values were simply codes for different categories. However, the 2014 sum column does in fact contain the total number across all sexes for each age category.
no_sums.group('AGE', sum)
Joining Tables. There are many situations in data analysis in which two different rows need to be considered together. Two tables can be joined into one, an operation that creates one long row out of two matching rows. These matching rows can be from the same table or different tables.
For example, we might want to estimate which age categories are expected to change significantly in the future. Someone who is 14 years old in 2014 will be 20 years old in 2020. Therefore, one estimate of the number of 20 year olds in 2020 is the number of 14 year olds in 2014. Between the ages of 1 and 50, annual mortality rates are very low (less than 0.5% for men and less than 0.3% for women [1]). Immigration also affects population changes, but for now we will ignore this confounding factor. Let's consider just females in this analysis.
females['AGE+6'] = females['AGE'] + 6
females
In order to relate the age in 2014 to the age in 2020, we will join this table with itself, matching values in the AGE column with values in the AGE in 2020 column.
joined = females.join('AGE', females, 'AGE+6')
joined
The resulting table has five columns. The first three are the same as before. The two new colums are the values for AGE and 2014 that appeared in a different row, the one in which that AGE appeared in the AGE+6 column. For instance, the first row contains the number of 6 year olds in 2014 and an estimate of the number of 6 year olds in 2020 (who were 0 in 2014). Some relabeling and selecting makes this table more clear.
future = joined.select(['AGE', '2014', '2014_2']).relabel('2014_2', '2020 (est)')
future
Adding a Change column and sorting by that change describes some of the major changes in age categories that we can expect in the United States for people under 50. According to this simplistic analysis, there will be substantially more people in their late 30's by 2020.
predictions = future.where(future['AGE'] < 50)
predictions['Change'] = predictions['2020 (est)'] - predictions['2014']
predictions.sort('Change', descending=True)