# Initialize Otter
import otter
grader = otter.Notebook("project3.ipynb")
Project 3: Movie Classification¶
Welcome to the third and final project of Data 8! You will build a classification model that guesses whether a movie is a comedy or a thriller by using only the number of times chosen words appear in the movie’s screenplay. By the end of the project, you should know how to:
Build a k-nearest-neighbors classifier.
Test a classifier on data.
Logistics¶
Deadline. This project is due at 5:00pm PT on Friday, 5/1. You can receive 5 bonus points for submitting the project by 5:00pm PT on Thursday, 4/30. Projects will be accepted up to 1 day (24 hours) late. Projects submitted fewer than 24 hours after the deadline will receive 80% credit. Any submissions later than 24 hours after the deadline will not be accepted. It’s much better to be early than late, so start working now.
Checkpoint. For full credit on the checkpoint, you must complete the questions up to the checkpoint, pass all public autograder tests for those sections, and submit to the Pensieve Project 03 Checkpoint assignment by 5:00pm PT on Friday, 4/24. The checkpoint is worth 1 lab score. After you’ve submitted the checkpoint, you may still change your project answers before the final project deadline - only your final submission, to the “Project 03 Autograder” assignment, will be graded for correctness (including questions from before the checkpoint). You will have some lab time to work on these questions, but we recommend that you start the project before lab and leave time to finish the checkpoint afterward.
Partners. You may work with one other partner; your partner must be from your assigned lab section. Only one partner should submit the project notebook to Pensieve. If both partners submit, you will be docked 10% of your project grade. On Pensieve, the person who submits should also designate their partner so that both of you receive credit. Once you submit, click into your submission, and there will be an option to Add Group Member in the top right corner. You may also reference this walkthrough video on how to add partners on Pensieve.
Rules. Don’t share your code with anybody but your partner. You are welcome to discuss questions with other students, but don’t share the answers. The experience of solving the problems in this project will prepare you for exams (and life). If someone asks you for the answer, resist! Instead, you can demonstrate how you would solve a similar problem.
Support. You are not alone! Come to office hours, post on Ed, and talk to your classmates. If you want to ask about the details of your solution to a problem, make a private Ed post and the staff will respond. If you’re ever feeling overwhelmed or don’t know how to make progress, email your TA or tutor for help. You can find contact information for the staff on the course website.
Tests. The tests that are given are not comprehensive and passing the tests for a question does not mean that you answered the question correctly. For table manipulation questions, tests usually only check that your table has the correct column labels. Similarly, on multiple choice / select all that apply questions, tests are only checking that your response in the right format, not that it is correct. However, more tests will be applied to verify the correctness of your submission in order to assign your final score, so be careful and check your work! You might want to create your own checks along the way to see if your answers make sense. Additionally, before you submit, make sure that none of your cells take a very long time to run (several minutes).
Free Response Questions: Make sure that you put the answers to the written questions in the indicated cell we provide. Every free response question should include an explanation that adequately answers the question.
Advice. Develop your answers incrementally. To perform a complicated task, break it up into steps, perform each step on a different line, give a new name to each result, and check that each intermediate result is what you expect. You can add any additional names or functions you want to the provided cells. Make sure that you are using distinct and meaningful variable names throughout the notebook. Along that line, DO NOT reuse the variable names that we use when we grade your answers.
You never have to use just one line in this project or any others. Use intermediate variables and multiple lines as much as you would like!
All of the concepts necessary for this project are found in the textbook. If you are stuck on a particular problem, reading through the relevant textbook section will often help to clarify concepts.
The point breakdown for this assignment is given in the table below:
| Category | Points |
|---|---|
| Autograder (Coding questions) | 87 |
| Written | 13 |
| Total | 100 |
To get started, load datascience, numpy, and matplotlib. Make sure to also run the first cell of this notebook to load otter.
# Run this cell to set up the notebook, but please don't change it.
import numpy as np
import math
import datascience
from datascience import *
# These lines set up the plotting functionality and formatting.
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import warnings
warnings.simplefilter("ignore")Part 1: The Dataset¶
In this project, we are exploring movie screenplays. We’ll be trying to predict each movie’s genre from the text of its screenplay. In particular, we have compiled a list of 5,000 words that occur in conversations between movie characters. For each movie, our dataset tells us the frequency with which each of these words occurs in certain conversations in its screenplay. All words have been converted to lowercase.
Run the cell below to read the movies table. It may take up to a minute to load.
Note: Outputting the full movies table will make exporting your Jupyter notebook very slow because the movies table is massive. Please avoid returning or using .show() for the entire movies table in your future cells!
movies = Table.read_table('movies.csv')Here is one row of the table and some of the frequencies of words that were said in the movie.
movies.where("Title", "runaway bride").select(0, 1, 2, 3, 4, 14, 49, 1042, 4004)The above cell prints a few columns of the row for the comedy movie Runaway Bride. The movie contains 4895 words. The word “it” appears 115 times, as it makes up of the words in the movie. The word “england” doesn’t appear at all.
Additional context: This numerical representation of a body of text, which describes only the frequencies of individual words, is called a bag-of-words representation. Before the development of the BERT model for classification in 2018, bag-of-words was a common method of representing text in NLP. The bag-of-words representation is easy to interpret, but a lot of information is discarded: the order of the words, the context of each word, who said what, etc. It is therefore no longer commonly used. Still, investigating how to use a bag-of-words representation in a classifier builds useful intuitions about how to classify text.
At the end of this project, you’ll have a chance to work with a more effective, but less interpretable, representation that uses a pretrained neural network to represent text.
All movie titles are unique. The row_for_title function provides fast access to the one row for each title.
Note: All movies in our dataset have their titles lower-cased.
title_index = movies.index_by('Title')
def row_for_title(title):
"""Return the row for a title, similar to the following expression (but faster)
movies.where('Title', title).row(0)
"""
return title_index.get(title)[0]
row_for_title('toy story')For example, the fastest way to find the frequency of “fun” in the movie Toy Story is to access the 'fun' item from its row. Check the original table to see if this worked for you!
row_for_title('toy story').item('fun')Question 1.0
Set expected_row_sum to the number that you expect will result from summing all proportions in each row, excluding the first five columns. Think about what any one row adds up to.
# Set row_sum to a number that's the (approximate) sum of each row of word proportions.
expected_row_sum = ...grader.check("q1_0")This dataset was extracted from a dataset from Cornell University. After transforming the dataset (e.g., converting the words to lowercase, removing the inappropriate words, and converting the counts to frequencies), we created this new dataset containing the frequency of 5000 common words in each movie.
print('Words with frequencies:', movies.drop(np.arange(5)).num_columns)
print('Movies with genres:', movies.num_rows)1.1. Word Stemming¶
The columns other than “Title”, “Year”, “Rating”, “Genre”, and “# Words” in the movies table are all words that appear in some of the movies in our dataset. These words have been stemmed, or abbreviated heuristically, in an attempt to make different inflected forms of the same base word into the same string. For example, the column “manag” is the sum of proportions of the words “manage”, “manager”, “managed”, and “managerial” (and perhaps others) in each movie. This is a common technique used in machine learning and natural language processing.
Stemming makes it a little tricky to search for the words you want to use, so we have provided another table called vocab_table that will let you see examples of unstemmed versions of each stemmed word. Run the code below to load it.
Note: You should use vocab_table for the rest of Section 1.1, not vocab_mapping.
# Just run this cell.
vocab_mapping = Table.read_table('stem.csv')
stemmed = np.take(movies.labels, np.arange(3, len(movies.labels)))
vocab_table = Table().with_column('Stem', stemmed).join('Stem', vocab_mapping)
vocab_table.take(np.arange(1100, 1110))Question 1.1.1
Using vocab_table, find the stemmed version of the word “elements” and assign the value to stemmed_message.
stemmed_message = ...
stemmed_messagegrader.check("q1_1_1")Question 1.1.2
What stem in the dataset has the most words that are shortened to it? Assign most_stem to that stem.
most_stem = ...
most_stemgrader.check("q1_1_2")Question 1.1.3
What is the longest word in the dataset whose stem is the same length as the original word? Assign that to longest_uncut. Break ties alphabetically from Z to A (so if your options are “cat” or “bat”, you should pick “cat”). Note that when sorting letters, the letter a is smaller than the letter z. You may also want to sort more than once.
Hint 1: vocab_table has 2 columns: one for stems and one for the unstemmed (normal) word. Find the longest word that wasn’t cut at all (same length as stem).
Hint 2: apply may be helpful here! Check Python Reference.
Hint 3: In our solution, we found it useful to first add columns with the length of the word and the length of the stem, and then to add a column with the difference between those lengths. What will the difference be if the word is not shortened?
tbl_with_lens = ...
tbl_with_diff = ...
longest_uncut = ...
longest_uncutgrader.check("q1_1_3")Question 1.1.4
How many stems have only one word that is shortened to them? For example, if the stem “book” only maps to the word “books” and if the stem “a” only maps to the word “a,” both should be counted as stems that map only to a single word.
Assign count_single_stems to the count of stems that map to one word only.
count_single_stems = ...
count_single_stemsgrader.check("q1_1_4")Let’s explore our dataset before trying to build a classifier. To start, we’ll use the associated proportions to investigate the relationship between different words.
The first association we’ll investigate is the association between the proportion of words that are “outer” and the proportion of words that are “space”.
As usual, we’ll investigate our data visually before performing any numerical analysis.
Run the cell below to plot a scatter diagram of “space” proportions vs “outer” proportions and to create the outer_space table. Each point on the scatter plot represents one movie.
# Just run this cell!
outer_space = movies.select("outer", "space")
outer_space.scatter("outer", "space")
plots.axis([-0.0005, 0.001, -0.0005, 0.003]);
plots.xticks(rotation=45);Question 1.2.1
Looking at that chart it is difficult to see if there is an association. Calculate the correlation coefficient for the potential linear association between proportion of words that are “outer” and the proportion of words that are “space” for every movie in the dataset, and assign it to outer_space_r.
Hint: If you need a refresher on how to calculate the correlation coefficient check out Ch 15.1.
# These two arrays should make your code cleaner!
outer = movies.column("outer")
space = movies.column("space")
outer_su = ...
space_su = ...
outer_space_r = ...
outer_space_rgrader.check("q1_2_1")Question 1.2.2
Choose two different words in the dataset with a magnitude (absolute value) of correlation higher than 0.2 and plot a scatter plot with a line of best fit for them. Please do not pick “outer” and “space” or “san” and “francisco”. The code to plot the scatter plot and line of best fit is given for you, you just need to calculate the correct values to r, slope and intercept.
Hint 1: It’s easier to think of words with a positive correlation, i.e. words that are often mentioned together. Try to think of common phrases or idioms.
Hint 2: Refer to Section 15.2 of the textbook for the formulas. For additional past examples of regression, see Homework 9.
word_x = ...
word_y = ...
# These arrays should make your code cleaner!
arr_x = movies.column(word_x)
arr_y = movies.column(word_y)
x_su = ...
y_su = ...
r = ...
slope = ...
intercept = ...
# DON'T CHANGE THESE LINES OF CODE
movies.scatter(word_x, word_y)
max_x = max(movies.column(word_x))
plots.title(f"Correlation: {r}, magnitude greater than .2: {abs(r) >= 0.2}")
plots.plot([0, max_x * 1.3], [intercept, intercept + slope * (max_x*1.3)], color='gold');grader.check("q1_2_2")Question 1.2.3
Imagine that you picked the words “san” and “francisco” as the two words that you would expect to be correlated because they compose the city name San Francisco. Assign san_francisco to either the integer 1 or the integer 2 according to which statement is true regarding the correlation between “san” and “francisco.”
“san” can also precede other city names like San Diego and San Jose. This might lead to “san” appearing in movies without “francisco,” and would reduce the correlation between “san” and “francisco.”
“san” can also precede other city names like San Diego and San Jose. The fact that “san” could appear more often in front of different cities and without “francisco” would increase the correlation between “san” and “francisco.”
san_francisco = ...grader.check("q1_2_3")1.3. Splitting the dataset¶
Now, we’re going to use our movies dataset for two purposes.
First, we want to train movie genre classifiers.
Second, we want to test the performance of our classifiers.
Hence, we need two different datasets: training and test.
The purpose of a classifier is to classify unseen data that is similar to the training data. The test dataset will help us determine the accuracy of our predictions by comparing the actual genres of the movies with the genres that our classifier predicts. Therefore, we must ensure that there are no movies that appear in both sets. We do so by splitting the dataset randomly. The dataset has already been permuted randomly, so it’s easy to split. We just take the first 85% of the dataset for training and the rest for test.
Run the code below (without changing it) to separate the datasets into two tables.
Note: Outputting the full train_movies table will make exporting your Jupyter notebook very slow because the train_movies table is massive. Please avoid returning or using .show() for the entire train_movies table in your future cells!
# Here we have defined the proportion of our data
# that we want to designate for training as 17/20ths (85%)
# and, of our total dataset 3/20ths (15%) of the data is
# reserved for testing
training_proportion = 17/20
num_movies = movies.num_rows
num_train = int(num_movies * training_proportion)
num_test = num_movies - num_train
train_movies = movies.take(np.arange(num_train))
test_movies = movies.take(np.arange(num_train, num_movies))
print("Training: ", train_movies.num_rows, ";",
"Test: ", test_movies.num_rows)Question 1.3.1
Draw a horizontal bar chart with two bars that show the proportion of Comedy movies in each dataset (train_movies and test_movies). The two bars should be labeled “Training” and “Test”. Complete the function comedy_proportion first; it should help you create the bar chart.
Hint: Refer to Section 7.1 of the textbook if you need a refresher on bar charts.
def comedy_proportion(table):
# Return the proportion of movies in a table that have the comedy genre.
...
return ...
# The staff solution took multiple lines. Start by creating a table.
# If you get stuck, think about what sort of table you need for barh to work
...Part 2: K-Nearest Neighbors - A Guided Example¶
K-Nearest Neighbors (k-NN) is a classification algorithm. While it is no longer common to use k-NN with a bag-of-word representation of text (as we do below), the idea of informing prediction using nearest neighbors is still very common in modern machine learning systems.
Given some numerical attributes (also called features) of an unseen example, k-NN decides which category that example belongs to based on its similarity to previously seen examples. Predicting the category of an example is called labeling, and the predicted category is also called a label.
An attribute (feature) we have about each movie is the proportion of times a particular word appears in the movie, and the labels are two movie genres: comedy and thriller. The algorithm requires many previously seen examples for which both the attributes and labels are known: that’s the train_movies table.
To build understanding, we’re going to visualize the algorithm instead of just describing it.
2.1. Classifying a movie¶
In k-NN, we classify a movie by finding the k movies in the training set that are most similar according to the features we choose. We call those movies with similar features the nearest neighbors. The k-NN algorithm assigns the movie to the most common category among its k nearest neighbors.
Let’s limit ourselves to just 2 features for now, so we can plot each movie. The features we will use are the proportions of the words “water” and “feel” in the movie. Taking the movie Monty Python and the Holy Grail (in the test set), 0.000804074 of its words are “water” and 0.0010721 are “feel”. This movie appears in the test set, so let’s imagine that we don’t yet know its genre.
First, we need to make our notion of similarity more precise. We will say that the distance between two movies is the straight-line distance between them when we plot their features on a scatter diagram.
This distance is called the Euclidean (“yoo-KLID-ee-un”) distance, whose formula is .
For example, in the movie Clerks. (in the training set), 0.00016293 of all the words in the movie are “water” and 0.00154786 are “feel”. Its distance from Monty Python and the Holy Grail on this 2-word feature set is . (If we included more or different features, the distance could be different.)
A third movie, The Godfather (in the training set), has 0 “water” and 0.00015122 “feel”.
The function below creates a plot to display the “water” and “feel” features of a test movie and some training movies. As you can see in the result, Monty Python and the Holy Grail is more similar to Clerks. than to the The Godfather based on these features, which makes sense as both movies are comedy movies, while The Godfather is a thriller.
# Just run this cell.
def plot_with_two_features(test_movie, training_movies, x_feature, y_feature):
"""Plot a test movie and training movies using two features."""
test_row = row_for_title(test_movie)
distances = Table().with_columns(
x_feature, [test_row.item(x_feature)],
y_feature, [test_row.item(y_feature)],
'Color', ['unknown'],
'Title', [test_movie]
)
for movie in training_movies:
row = row_for_title(movie)
distances.append([row.item(x_feature), row.item(y_feature), row.item('Genre'), movie])
distances.scatter(x_feature, y_feature, group='Color', labels='Title', s=50)
training = ["clerks.", "the godfather"]
plot_with_two_features("monty python and the holy grail", training, "water", "feel")
plots.axis([-0.0008, 0.001, -0.004, 0.007]);Question 2.1.1
Compute the Euclidean distance (defined in the section above) between the two movies, Monty Python and the Holy Grail and The Godfather, using the water and feel features only. Assign it the name one_distance.
Hint 1: If you have a row, you can use item to get a value from a column by its name. For example, if r is a row, then r.item("Genre") is the value in column "Genre" in row r.
Hint 2: Refer to the beginning of Part 1 if you don’t remember what row_for_title does.
Hint 3: In the formula for Euclidean distance, think carefully about what x and y represent. Refer to the example in the text above if you are unsure.
python = row_for_title("monty python and the holy grail")
godfather = row_for_title("the godfather")
one_distance = ...
one_distancegrader.check("q2_1_1")Below, we’ve added a third training movie, The Silence of the Lambs. Before, the point closest to Monty Python and the Holy Grail was Clerks., a comedy movie. However, now the closest point is The Silence of the Lambs, a thriller movie.
training = ["clerks.", "the godfather", "the silence of the lambs"]
plot_with_two_features("monty python and the holy grail", training, "water", "feel")
plots.axis([-0.0008, 0.001, -0.004, 0.007]);Question 2.1.2
Complete the function distance_two_features that computes the Euclidean distance between any two movies, using two features. The last two lines call your function to show that Monty Python and the Holy Grail is closer to The Silence of the Lambs than it is to Clerks.
def distance_two_features(title0, title1, x_feature, y_feature):
"""Compute the distance between two movies with titles title0 and title1.
Only the features named x_feature and y_feature are used when computing the distance.
"""
row0 = ...
row1 = ...
...
for movie in make_array("clerks.", "the silence of the lambs"):
movie_distance = distance_two_features(movie, "monty python and the holy grail", "water", "feel")
print(movie, 'distance:\t', movie_distance)grader.check("q2_1_2")Question 2.1.3
Define the function distance_from_python so that it works as described in its documentation/docstring (the string right below where the function is defined).
Note: Your solution should not use arithmetic operations directly. Instead, it should make use of previously defined functions!
def distance_from_python(title):
"""Return the distance between the given movie and "monty python and the holy grail",
based on the features "water" and "feel".
This function takes a single argument:
title: A string, the name of a movie.
"""
...
# Calculate the distance between "Clerks." and "Monty Python and the Holy Grail"
distance_from_python('clerks.')grader.check("q2_1_3")Question 2.1.4
Using the features water and feel, what are the names and genres of the 5 movies in the training set closest to Monty Python and the Holy Grail? To answer this question, make a table named close_movies containing those 5 movies with columns "Title", "Genre", "water", and "feel", as well as a column called "distance from python" that contains the distance from Monty Python and the Holy Grail. The table should be sorted in ascending order by "distance from python".
Note: Why are smaller distances from Monty Python and the Holy Grail more helpful in helping us classify the movie? (In other words, why is it helpful to focus on our nearest neighbors?)
Hint: Your final table should only have 5 rows. How can you get the first five rows of a table?
# The staff solution took multiple lines.
...
close_movies = ...
close_moviesgrader.check("q2_1_4")Question 2.1.5
Next, we’ll classify Monty Python and the Holy Grail based on the genres of the closest movies.
To do so, define the function most_common so that it works as described in its documentation below.
def most_common(label, table):
"""This function takes two arguments:
label: The label of a column, a string.
table: A table.
It returns the most common value in the label column of the table.
In case of a tie, it returns any one of the most common values.
"""
...
# Calling most_common on your table of 5 nearest neighbors classifies
# "monty python and the holy grail" as a thriller movie, 3 votes to 2.
most_common('Genre', close_movies)grader.check("q2_1_5")Congratulations are in order — you’ve classified your first movie! However, we can see that the classifier doesn’t work very well, since it categorized Monty Python and the Holy Grail as a thriller movie (unless you count the thrilling holy hand grenade scene). In next part, we will try to do better!
Checkpoint (due Friday 4/24 by 5:00 pm PT)¶

Cookie the Frog gives your project checkpoint the Stare of Approval.
Run the following cells and submit to the Pensive assignment titled Project 03 Checkpoint. Before that , remove any tbl.show() calls (calls to .show with no argument) and any unneccessary print statements. Forgetting to do this may cause issues when running your notebook on Pensieve.
NOTE: This checkpoint does not represent the halfway point of the project. You are highly encouraged to continue on to the next section early.
To get full credit for this checkpoint, you must pass all the public autograder tests above this cell. The cell below will rerun all of the autograder tests for Part 1 and Part 2 so that you can double check your work.
checkpoint_tests = ["q1_0", "q1_1_1", "q1_1_2", "q1_1_3", "q1_1_4",
"q1_2_1", "q1_2_3", "q1_2_2",
"q2_1_1", "q2_1_2", "q2_1_3", "q2_1_4", "q2_1_5"]
for test in checkpoint_tests:
display(grader.check(test))Submission¶
Make sure you have run all cells in your notebook in order before running the cell below, so that all images/graphs appear in the output. You can do this by going to Cell > Run All. The cell below will generate a zip file for you to submit. Please save before exporting!
Reminders:
Please remember to add your partner to your Pensieve submission. If you resubmit, make sure to re-add your partner, as Pensieve does not save any partner information.
Make sure to wait until the autograder finishes running to ensure that your submission was processed properly and that you submitted to the correct assignment.
# Save your notebook first, then run this cell to export your submission.
grader.export(pdf=False, force_save=True)Now, we’re going to extend our classifier to consider more than two features at a time to see if we can get a better classification of our movies.
Euclidean distance still makes sense with more than two features. For n different features, we compute the difference between corresponding feature values for two movies, square each of the n differences, sum up the resulting numbers, and take the square root of the sum.
Question 3.0
Write a function called distance to compute the Euclidean distance between two arrays of numerical features (e.g. arrays of the proportions of times that different words appear). The function should be able to calculate the Euclidean distance between two arrays of arbitrary (but equal) length.
Next, use the function you just defined to compute the distance between the first and second movie in the training set using all of the features. (Remember that the first five columns of your tables are not features.)
Hint 1: To convert rows to arrays, use np.array. For example, if t was a table, np.array(t.row(0)) converts row 0 of t into an array.
Hint 2: Make sure to drop the first five columns of the table before you compute distance_first_to_second, as these columns do not contain any features (the proportions of words).
def distance(features_array1, features_array2):
"""The Euclidean distance between two arrays of feature values."""
...
array_values_movie_1 = ...
array_values_movie_2 = ...
distance_first_to_second = ...
distance_first_to_secondgrader.check("q3_0")3.1. Creating your own feature set¶
Unfortunately, using all of the features has some downsides. One clear downside is the lack of computational efficiency -- computing Euclidean distances just takes a long time when we have lots of features. You might have noticed that in the last question!
So we’re going to select just 20. We’d like to choose features that are very discriminative. That is, features which lead us to correctly classify as much of the test set as possible. This process of choosing features that will make a classifier work well is sometimes called feature selection, or, more broadly, feature engineering. This once-critical step in machine learning has become less important as neural networks automate the process of feature selection, but there are still settings in which manual selection of features can prove worthwhile.
In this question, we will help you get started on selecting more effective features for distinguishing comedy from thriller movies. The plot below (generated for you) shows the average number of times each word occurs in a comedy movie on the horizontal axis and the average number of times it occurs in an thriller movie on the vertical axis.
Note: The line graphed is the line of best fit, NOT the line y=x.
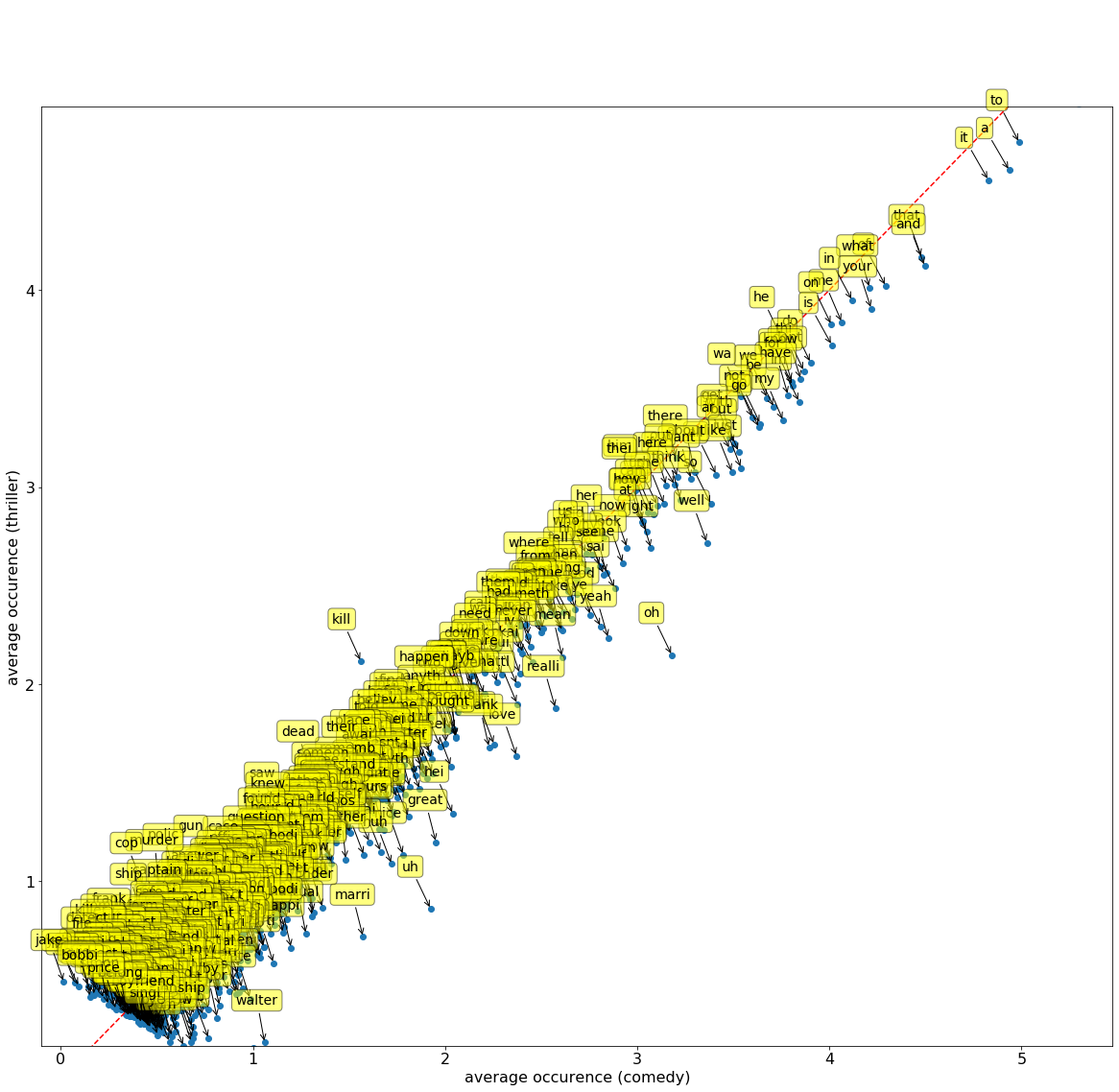
Run the cell below for an interactive plot! Hover over the invididual points to see what word each point is! For reference, the character you may see in some of the entries means to multiply by 10-6 or 0.000001
from IPython.display import HTML
HTML("https://raw.githubusercontent.com/jonathanferrari/static/main/word_plot.html")Questions 3.1.1 through 3.1.4 will ask you to interpret the plot above. If no words are present in the specified area of the graph, try to think what characteristics would those words exhibit if points were located there. For each question, select one of the following choices and assign its number to the provided name.
The word is common in both comedy and thriller movies
The word is uncommon in comedy movies and common in thriller movies
The word is common in comedy movies and uncommon in thriller movies
The word is uncommon in both comedy and thriller movies
It is not possible to say from the plot
Question 3.1.1
What properties do words in the bottom left corner of the plot have? Your answer should be a single integer from 1 to 5, corresponding to the correct statement from the choices above.
bottom_left = ...grader.check("q3_1_1")Question 3.1.2
What properties do words in the bottom right corner have?
bottom_right = ...grader.check("q3_1_2")Question 3.1.3
What properties do words in the top right corner have?
top_right = ...grader.check("q3_1_3")Question 3.1.4
What properties do words in the top left corner have?
top_left = ...grader.check("q3_1_4")Question 3.1.5
If we see a movie with a lot of words that are common for comedy movies but uncommon for thriller movies, what would be a reasonable guess about the genre of the movie? Assign movie_genre to the integer corresponding to your answer:
It is a thriller movie.
It is a comedy movie.
movie_genre_guess = ...grader.check("q3_1_5")Question 3.1.6
Using the plot above, make an array of at least 10 common words that you think might let you distinguish between comedy and thriller movies. Make sure to choose words that are frequent enough that every movie contains at least one of them. Don’t just choose the most frequent words though--if they appear too frequently, they may not be helpful for distinguishing between comedy and thriller.
# Set my_features to an array of at least 10 features (strings that are column labels)
my_features = ...
# Select the 10 features of interest from both the train and test sets
train_my_features = train_movies.select(my_features)
test_my_features = test_movies.select(my_features)grader.check("q3_1_6")This test makes sure that you have chosen words such that at least one appears in each movie. If you can’t find words that satisfy this test just through intuition, try writing code to print out the titles of movies that do not contain any words from your list, then look at the words they do contain.
Question 3.1.7
In two sentences or less, describe how you selected your features.
Type your answer here, replacing this text.
Next, let’s classify the first movie from our test set using these features. You can examine the movie by running the cells below. Do you think it will be classified correctly?
print("Movie:")
test_movies.take(0).select('Title', 'Genre').show()
print("Features:")
test_my_features.take(0).show()As before, we want to look for the movies in the training set that are most like our test movie. We will calculate the Euclidean distances from the test movie (using my_features) to all movies in the training set. You could do this with a for loop, but to make it computationally faster, we have provided a function, fast_distances, to do this for you. Read its documentation to make sure you understand what it does. (You don’t need to understand the code in its body unless you want to.)
# Just run this cell to define fast_distances.
def fast_distances(test_row, train_table):
"""Return an array of the distances between test_row and each row in train_table.
Takes 2 arguments:
test_row: A row of a table containing features of one
test movie (e.g., test_my_features.row(0)).
train_table: A table of features (for example, the whole
table train_my_features)."""
assert train_table.num_columns < 50, "Make sure you're not using all the features of the movies table."
assert type(test_row) != datascience.tables.Table, "Make sure you are passing in a row object to fast_distances."
assert len(test_row) == len(train_table.row(0)), "Make sure the length of test row is the same as the length of a row in train_table."
counts_matrix = np.asmatrix(train_table.columns).transpose()
diff = np.tile(np.array(list(test_row)), [counts_matrix.shape[0], 1]) - counts_matrix
np.random.seed(0) # For tie breaking purposes
distances = np.squeeze(np.asarray(np.sqrt(np.square(diff).sum(1))))
eps = np.random.uniform(size=distances.shape)*1e-10 #Noise for tie break
distances = distances + eps
return distancesQuestion 3.1.8
Use the fast_distances function provided above to compute the distance from the first movie in your test set to all the movies in your training set, using your set of features. Make a new table called genre_and_distances with one row for each movie in the training set and two columns:
The
"Genre"of the training movieThe
"Distance"from the first movie in the test set
Ensure that genre_and_distances is sorted in ascending order by distance to the first test movie.
Hint: Think about how you can use the variables you defined in 3.1.6.
# The staff solution took multiple lines of code.
genre_and_distances = ...
genre_and_distancesgrader.check("q3_1_8")Question 3.1.9
Now compute the 7-nearest neighbors classification of the first movie in the test set. That is, decide on its genre by finding the most common genre among its 7 nearest neighbors in the training set, according to the distances you’ve calculated. Then check whether your classifier chose the right genre. (Depending on the features you chose, your classifier might not get this movie right, and that’s okay.)
Hint 1: You should use the most_common function that was defined earlier.
Hint 2: You should use a comparison operator.
# Set my_assigned_genre to the most common genre among these.
my_assigned_genre = ...
# Set my_assigned_genre_was_correct to True if my_assigned_genre
# matches the actual genre of the first movie in the test set, False otherwise.
my_assigned_genre_was_correct = ...
print("The assigned genre, {}, was{}correct.".format(my_assigned_genre, " " if my_assigned_genre_was_correct else " not "))grader.check("q3_1_9")3.2. A classifier function¶
Now we can write a single function that encapsulates the whole process of classification.
Question 3.2.1
Write a function called classify. It should take the following three arguments:
A list of distances between the test features and training features (e.g.,
fast_distances(test_my_features.row(0), train_my_features)).An array of classes (e.g. the labels “comedy” or “thriller”) that has as many items as there are distances, and in the same order. Hint: What are the labels of each row in the training set?
k, the number of neighbors to use in classification.
It should return the class (the string 'comedy' or the string 'thriller') a k-nearest neighbor classifier picks for the given row of features.
def classify(distances, train_labels, k):
"""Return the most common class among k nearest neighbors given the distances and labels."""
genre_and_distances = ...
...grader.check("q3_2_1")Question 3.2.2
Assign godzilla_genre to the genre predicted by a 15-nearest neighors classifier for the movie “godzilla” in the test set, using your classify function and your 10 features.
Hint: The row_for_title function will not work here.
# The staff solution first defined a row called godzilla_features.
godzilla_features = ...
godzilla_distances = fast_distances(godzilla_features, train_my_features)
godzilla_genre = ...
godzilla_genregrader.check("q3_2_2")Finally, when we evaluate our classifier, it will be useful to have a classification function that is specialized to use a fixed training set and a fixed value of k.
Question 3.2.3
Create a classification function that takes as its argument a row containing your 10 features and classifies that row using the 15-nearest neighbors algorithm with train_my_features as its training set.
def classify_feature_row(row):
...
# When you're done, this should produce 'thriller' or 'comedy'.
classify_feature_row(test_my_features.row(0))grader.check("q3_2_3")Now that it’s easy to use the classifier, let’s see how accurate it is on the whole test set.
Question 3.3.1
Use classify_feature_row and apply to classify every movie in the test set. Assign these guesses as an array to test_guesses. Then, compute the proportion of correct classifications.
Hint 1: If you do not specify any columns in t.apply(...), your function will be applied to every row object in Table t.
Hint 2: Which dataset do you want to apply this function to?
test_guesses = ...
proportion_correct = ...
proportion_correctgrader.check("q3_3_1")Question 3.3.2
An important part of evaluating your classifiers is figuring out where they make mistakes. Assign the name test_movie_correctness to a table with three columns, 'Title', 'Genre', and 'Was correct'.
The
'Genre'column should contain the original genres, not the ones you predicted.The
'Was correct'column should containTrueorFalsedepending on whether or not the movie was classified correctly.
# Feel free to use multiple lines of code
# but make sure to assign test_movie_correctness to the proper table!
test_movie_correctness = ...
test_movie_correctness.sort('Was correct', descending = True).show(5)grader.check("q3_3_2")Question 3.3.3
Do you see a pattern in the types of movies your classifier misclassifies? In two sentences or less, describe any patterns you see in the results or any other interesting findings from the table above. If you need some help, try looking up the movies that your classifier got wrong on Wikipedia.
Type your answer here, replacing this text.
At this point, you’ve gone through one cycle of classifier design. Let’s summarize the steps:
From available data, select test and training sets.
Choose an algorithm you’re going to use for k-NN classification.
Identify some features.
Define a classifier function using your features and the training set.
Evaluate its performance (the proportion of correct classifications) on the test set.
Part 4: Explorations¶
Now that you know how to evaluate a classifier, it’s time to build another one.
Your friends are big fans of comedy and thriller movies. They have created their own dataset of movies that they want to watch, but they need your help in determining the genre of each movie in their dataset (comedy or thriller). You have never seen any of the movies in your friends’ dataset, so none of your friends’ movies are present in your training or test set from earlier. In other words, this new dataset of movies can function as another test set that we are going to make predictions on based on our original training data.
Run the following cell to load your friends’ movie data.
Note: The
friend_moviestable has 5005 columns, so we only show the first 105 to stop this cell from crashing your notebook.
friend_movies = Table.read_table('friend_movies.csv')
friends_subset = friend_movies.select(np.arange(106))
friends_subset.show(5)Question 4.1
Your friend’s computer is not as powerful as yours, so they tell you that the classifier you create for them can only have up to 5 words as features. Develop a new classifier with the constraint of using no more than 5 features. Assign new_features to an array of your features.
Your new function should have the same arguments as classify_feature_row and return a classification. Name it another_classifier. Then, output your accuracy using code from earlier. We can look at the value to compare the new classifier to your old one.
Some ways you can change your classifier are by using different features or trying different values of k. (Of course, you still have to use train_movies as your training set!)
Make sure you don’t reassign any previously used variables here, such as proportion_correct from the previous question.
Note: There’s no one right way to do this! Just make sure that you can explain your reasoning behind the new choices.
new_features = ...
train_new = train_movies.select(new_features)
test_new = friend_movies.select(new_features)
def another_classifier(row):
...grader.check("q4_1")Question 4.2
Do you see a pattern in the mistakes your new classifier makes? How good an accuracy were you able to get with your limited classifier? Did you notice an improvement from your first classifier to the second one? Describe in three sentences or less.
Hint: You may not be able to see a pattern.
Type your answer here, replacing this text.
Question 4.3
Given the constraint of five words, how did you select those five? Describe in two sentences or less.
Type your answer here, replacing this text.
This optional part will not be scored.
Neural networks are an effective way to use numerical optimization to detect features automatically as an alternative to manual feature selection, which is what we did to build our own classifier in Parts 1-4. However, instead of picking an interpretable set of word features, neural networks typically represent text as a sequence of numerical features that don’t individually have meaning, but together are very effective for computing similarity between different text documents.
For text classification, the best performing approaches all involve a foundation model, which is a neural network trained on large quantities of web text (such as Wikipedia) that can take in text as input and generate a fixed-length list of numerical features about that text called an embedding or embedding vector. These features are trained to predict more text (such as hidden words in a sentence), but they can be used to predict many other properties of text (such as the genre of a movie script) because similar documents will have similar embeddings.
The file embeddings.csv contains a table with 333 columns, with the title of each movie as a column label, and 768 rows of numbers. Each column contains the numeric “features” of the embedding that a neural network chose to represent the screenplay of that movie. The length 768 is called the dimension of the embedding vector and is determined by the neural network. Embeddings with larger dimension carry more information, but take more time and memory to compute.
These particular embeddings were generated from full screenplays using the public sentence-transformers/all-mpnet-base-v2 model.
This model can only embed about 200 words at a time, and so each screenplay was split into overlapping 200-word chunks, each chunk was embedded separately, and the per-chunk embeddings were averaged.
5.1. Load the embeddings¶
Generating embeddings took about an hour on a 2024 Macbook Air and involved a few features of Python that are beyond the scope of Data 8, but most of the work was done by this code:
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer
MODEL_NAME = 'sentence-transformers/all-mpnet-base-v2'
model = SentenceTransformer(MODEL_NAME)
embeddings = model.encode(
screenplay_texts, # the text had to be read from files first
batch_size=32,
normalize_embeddings=True,
convert_to_numpy=True)However, generating embeddings required access to the text of the screenplays, which are protected by copyright and therefore can’t be published as part of this project. (Collecting all the screenplays was the hard part of setting this up!) Therefore, in this project we’ll just load embeddings rather than generating them.
Important: The embeddings table has one column per movie, and so for some movie title t, embeddings.column(t) is an array containing the embedding for that movie. By contrast, the movies table had one row per movie.
embeddings = Table.read_table('embeddings.csv')
print('Rows:', embeddings.num_rows, 'Columns:', embeddings.num_columns)
print('The first 10 numbers in the ghostbusters embedding:')
embeddings.take(np.arange(10)).column('ghostbusters')5.2. Implementing a k-NN Classifier Using These Embeddings as Features¶
The similarity of two screenplay embeddings uses a different notion of distance than the Euclidean distance we used before. Instead of summing the square difference between feature values, we sum the product of feature values. This way of computing similarity, called a dot product or cosine similarity, is the standard way that embeddings are compared in neural networks. Due to how the embeddings were constructed, the cosine similarity is always between 0 and 1. Larger similarities correspond to smaller distances, so we subtract the cosine similarity from 1 to get a distance between embeddings.
def embedding_distance(embedding1, embedding2):
"""1 - the cosine similarity between two arrays of feature values."""
return 1 - sum(embedding1 * embedding2)
def embedding_distances(one_embedding, embedding_table):
"""Returns the embedding distances between a single movie `one_embedding` and all movies in `embedding_table`"""
return [embedding_distance(one_embedding, other) for other in embedding_table.columns]We split the embeddings into the same collection of train and test movies used previously.
train_embeddings = embeddings.select(train_movies.column(0))
test_embeddings = embeddings.select(test_movies.column(0))Run the cells below to see what train_embeddings and test_embeddings look like.
train_embeddings.show(5)test_embeddings.show(5)classify_embedding predicts a genre label for a test movie embedding by finding the k training movies with the highest cosine similarity and returning their most common genre.
def classify_embedding(test_embedding, train_embeddings, train_labels, k):
distances = embedding_distances(test_embedding, train_embeddings)
return classify(distances, train_labels, k)
# Try it on the first test movie
print(test_embeddings.labels[0])
classify_embedding(test_embeddings.column(0), train_embeddings, train_movies.column('Genre'), 7)5.3. Evaluate on the test set¶
It’s up to you to complete the evaluation of a k-NN classifier that uses these embeddings. Call classify_embedding on each of the test_embeddings and see how often the genre is correct. Assign your accuracy to accuracy. With k=15, you should get an accuracy of roughly 90%. Not bad, considering we didn’t have to perform any feature selection!
Hint: The movie in column i of test_embeddings corresponds to the same movie in row i of test_movies.
embedding_predictions = ...
...
predicted_label = ...
embedding_predictions = ...
accuracy = ...
accuracygrader.check("q5_3")Next, you could investigate the mistakes that this classifier makes and compare it to the one you created using word frequency features.
Please make sure you have added your partner on Pensive. If you have done it, set add_partner to True.
Note: The variable should be set to True if you don’t have a partner.
add_partner = ...grader.check("q5_1")
Congratulations -- MaoMao is proud of you for finishing Project 3!¶
You’re finished! Time to submit.
Reminders:
Please remember to add your partner to your Pensive submission. If you resubmit, make sure to re-add your partner, as Pensive does not save any partner information.
Please note that filling out the Official Project 2 Partner form is NOT the same as adding your partner to your Pensive submission.
Remove any
tbl.show()calls (calls to.showwith no argument) and any unneccessary print statements. Forgetting to do this may cause issues when running your notebook on Pensive.Make sure to wait until the autograder finishes running to ensure that your submission was processed properly and that you submitted to the correct assignment.
To double-check your work, the cell below will rerun all of the autograder tests.
grader.check_all()Submission¶
Make sure you have run all cells in your notebook in order before running the cell below, so that all images/graphs appear in the output. The cell below will generate a zip file for you to submit. Please save before exporting!
# Save your notebook first, then run this cell to export your submission.
grader.export(pdf=False)