from datascience import *
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plots
plots.style.use('fivethirtyeight')
import warnings
warnings.simplefilter("ignore")Comparing Two Samples¶
births = Table.read_table('baby.csv')birthsLoading...
smoking_and_birthweight = births.select('Maternal Smoker', 'Birth Weight')smoking_and_birthweight.group('Maternal Smoker')Loading...
smoking_and_birthweight.hist('Birth Weight', group='Maternal Smoker')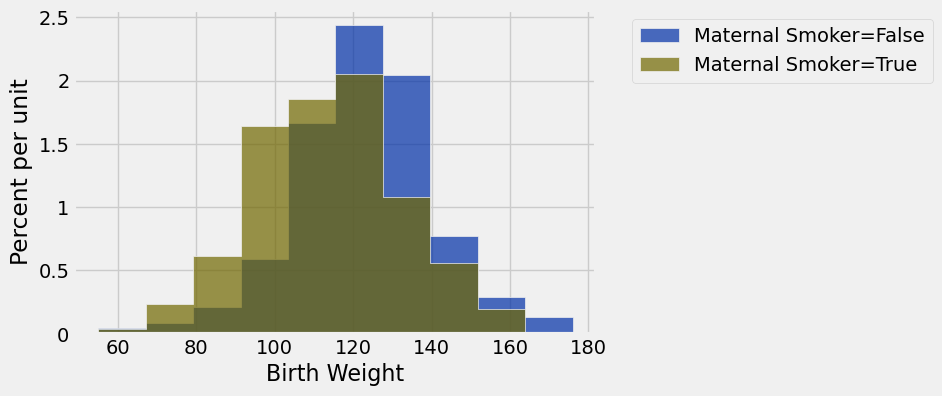
Test Statistic¶
[Question] What values of our statistic are in favor of the alternative: positive or negative?
means_table = smoking_and_birthweight.group('Maternal Smoker', np.average)
means_tableLoading...
means = means_table.column(1)
observed_difference = means.item(1) - means.item(0)
observed_difference-9.266142572024918def difference_of_means(table, numeric_label, category_label):
"""
Takes:
- name of table
- column label of numerical variable
- column label of categorical variable
Returns: Difference of means of the two groups
"""
#table with the two relevant columns
reduced = table.select(numeric_label, category_label)
# table containing group means
means_table = reduced.group(category_label, np.average)
# array of group means
means = means_table.column(1)
return means.item(1) - means.item(0)difference_of_means(births, 'Birth Weight', 'Maternal Smoker')-9.266142572024918Random Permutation (Shuffling)¶
staff = Table().with_columns(
'Names', make_array('Jim', 'Pam', 'Dwight', 'Michael'),
'Ages', make_array(29, 28, 34, 41)
)staff.sample()Loading...
staff.sample(with_replacement = False)Loading...
staff.with_column('Shuffled', staff.sample(with_replacement = False).column(0))Loading...
Simulation Under Null Hypothesis¶
smoking_and_birthweightLoading...
shuffled_labels = smoking_and_birthweight.sample(with_replacement=False).column('Maternal Smoker')original_and_shuffled = smoking_and_birthweight.with_column(
'Shuffled Label', shuffled_labels
)original_and_shuffledLoading...
difference_of_means(original_and_shuffled, 'Birth Weight', 'Shuffled Label')1.0220302573243742difference_of_means(original_and_shuffled, 'Birth Weight', 'Maternal Smoker')-9.266142572024918Permutation Test¶
def one_simulated_difference(table, numeric_label, category_label):
"""
Takes:
- name of table
- column label of numerical variable
- column label of categorical variable
Returns: Difference of means of the two groups
"""
# array of shuffled labels
shuffled_labels = table.sample(with_replacement = False).column(category_label)
# table of numerical variable and shuffled labels
shuffled_table = table.select(numeric_label).with_column('Shuffled Label', shuffled_labels)
return difference_of_means(shuffled_table, numeric_label, 'Shuffled Label') one_simulated_difference(births, 'Birth Weight', 'Maternal Smoker')-0.6342367871779686differences = make_array()
for i in np.arange(2000):
new_difference = one_simulated_difference(births, 'Birth Weight', 'Maternal Smoker')
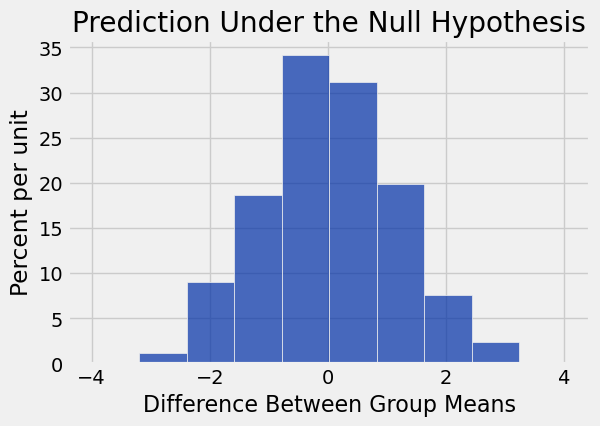
differences = np.append(differences, new_difference)Table().with_column('Difference Between Group Means', differences).hist()
print('Observed Difference:', observed_difference)
plots.title('Prediction Under the Null Hypothesis');Observed Difference: -9.266142572024918